46: Traversing the DOM
11th October 2012: Material moved to webplatform.org
The Opera web standards curriculum has now been moved to the docs section of the W3C webplatform.org site. Go there to find updated versions of these docs, and much more besides!
12th April 2012: This article is obsolete
The web standards curriculum has been donated to the W3C web education community group, to become part of a much bigger educational resource. It is constantly being updated so that it remains current with modern web design practices and technologies. To find the most up-to-date web standards curriculum, visit the web education community group Wiki. Please make changes to this Wiki yourself, or suggest changes to Chris Mills, who is also the chair of the web education community group.
Introduction
It’s hard to come up with any example of useful JavaScript code on the web that doesn’t interact in some way with an HTML document. Generally speaking, your code needs to read in values from the page, process them in some way, and then generate output in the form of visible changes or informational messages. As your next step towards the goal of creating responsive interfaces for your pages and applications, this article and the next will introduce the Document Object Model, which provides the mechanism for inspecting and manipulating the semantic and presentational layers that you create.
After reading this article, you’ll have a good understanding of what the DOM is, and how you can use it to navigate through an HTML page in order to find the exact spot at which you need to gather some data or make a change. The next article in the series (Creating and modifying HTML) will pick up there, outlining the methods by which you can manipulate the data on the page, changing values or creating entirely new elements and attributes.
The structure of this article is as follows:
Planting seeds
The DOM, as you might guess from the name Document Object Model, is a model of the HTML document which is created by the browser when it loads up your web page. JavaScript has access to all of the information is this model. Let’s step back a moment, and consider what exactly is being modeled.
When I build a page, my goal is to add meaning to raw content by mapping it to the HTML tags I have available: One bit of content is a paragraph, so I’ll use a p tag; the next is a link, so I’ll use an a tag, and so on. I also encode relationships between elements: input fields each have a label, and might sit together inside a fieldset. Moreover, I’ll go a bit beyond this basic set of HTML tags by adding id and class attributes where appropriate in order to infuse the page with more structures I can use to style or manipulate it. Once this HTML framework is built, I’ll use CSS to dress up those pure semantics with stylish presentation. Et voilà, you’ve created a page that will delight your users.
But that’s not all. I’ve created a document that’s simply dripping with meta-information that I can manipulate using JavaScript. I can find specific elements or groups of elements and delete, add, and modify them according to user-defined variables; I can find presentational information (CSS) and modify styles on the fly; I can validate the information users enter into forms; and a whole host of other things. For JavaScript to do these things, it needs access to information, and the DOM provides JavaScript with all of this.
It’s also important to note that well-structured HTML and CSS form the seed from which JavaScript's model for the page will grow. The model of a poorly constructed document will differ in undesirable ways from your expectations, and behave inconsistently across browsers. It’s vital, then, that your HTML and CSS be both well-formed and valid in order to ensure that JavaScript ends up with exactly the model you think it should.
Growing trees
After creating and styling your document, the next step is to hand it off to a browser to display to your users. This is where the DOM comes into play, reading through the document you’ve written, and dynamically generating a DOM you can use within your programs. Specifically, the DOM represents the HTML page as a tree, in much the same way you might represent your ancestry as a “family tree”. Each element on the page is contained in the DOM as a node, with branches linking to elements it directly contains (its children), and to the element that directly contains it (its parent). Let’s work through a simple HTML document to make these relationships clear:
<html>
<head>
<title>This is a Document!</title>
</head>
<body>
<h1>This is a header!</h1>
<p id="excitingText">
This is a paragraph! <em>Excitement</em>!
</p>
<p>
This is also a paragraph, but it's not nearly as exciting as the last one.
</p>
</body>
</html>As you can see, the entire document is contained within an html element. That element directly contains two others: head and body. Those show up in our model as its children, and they each point to html as their parent. And so it goes, down through the document hierarchy, with each element pointing to its direct descendants as children, and to its direct ancestor as parent:
titleis a child ofhead.bodyhas three children — twopelements and anh1element.- The
pelement with theid="excitingTexthas a child of its own — anemelement. - The plain text content of the elements (ie “This is a Document!”) is also represented in the DOM, as text nodes. These have no children of their own, but do point to their containing elements as parents.
So, the DOM hierarchy we end up for the above HTML document is represented visually something like Figure 1:
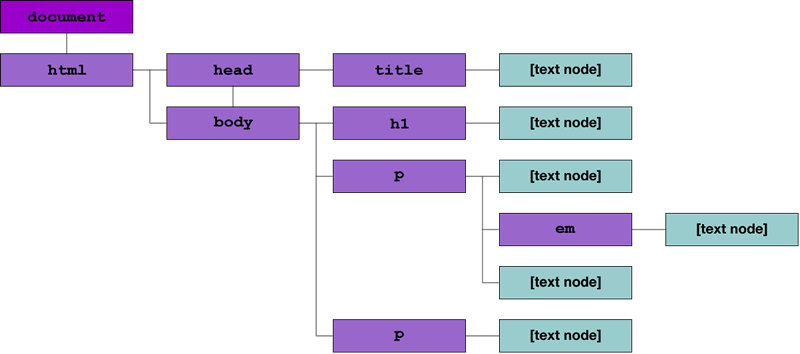
Figure 1: The above HTML document represented visually as a DOM tree.
It’s a straightforward mapping from the HTML document to this tree structure, which succinctly captures the direct relationships between elements on the page, making the hierarchy clear. You’ll notice, however, that I’ve added a node labeled document above the html node. This is the document’s root, and acts as JavaScript’s most-visible hook into the tree.
Nodes
Before I shimmy up the tree and start swinging from branch to branch, let’s take a moment to examine in some detail what exactly I’ll be hanging on to.
Each node in the DOM tree is an object representing a single element on the page. Nodes understand their relationship to other nodes in their immediate vicinity, and contain a good deal of information about themselves. In much the same way as a child might clamber from one branch to the next closest in a backyard oak, I can gather all the information from a node that I need to get to its parent or to its children.
As you might expect, given JavaScript’s object-nature, the information I’m looking for in this case is exposed via the node’s properties. Specifically, the parentNode and childNodes properties. As each element on the page has at most one parent, the parentNode property is straightforward: it simply gives you access to the node’s parent. Nodes can have any number of children, however, so the childNodes property is actually an array. Each element of the array points to one child, in the same order they appear in the document. Our example document’s body element would therefore have a childNodes array containing the h1, the first p, then the second p, in that order.
These aren’t the only interesting properties of nodes, of course. But this is a good start. So what code do I use to get my hands on one of these nodes in the first place? Where do I start my explorations?
Branch to branch
The best place to begin is at the document’s root, accessible via an object creatively named document. As document is right at the root, it doesn’t have a parentNode, but it does have a single child: the html element node, which we can access via document’s childNodes array:
var theHtmlNode = document.childNodes[0];This line of code creates a new variable named theHtmlNode, and assigns it the value of the document object’s first child (remember that JavaScript arrays start numbering with 0, not 1). You can confirm that you’ve gotten your hands on the html node by examining theHtmlNode’s nodeName property, which gives vital information about the exact kind of node you’re dealing with:
alert( "theHtmlNode is a " + theHtmlNode.nodeName + " node!" );This code pops up an alert box that reads “theHtmlNode is a HTML node!”. Great! The nodeName property gives you access to the node’s type. For element nodes, the property contains the tag name in upper case: here it’s “HTML”; for a link it would be “A”, for a paragraph “P”, and so on. A text node’s nodeName property is “#text”, and document’s nodeName is “#document”.
You also know that theHtmlNode should contain a reference to its parent. You can check that it’s working the way it's expected to with the following test:
if ( theHtmlNode.parentNode == document ) {
alert( "Hooray! The HTML node's parent is the document object!" );
}This does just as we were expecting. Using this information, let’s write some code to get a reference to the first paragraph in the example document’s body. This is the second child of the body element, which is the second child of the html element, which is the first child of the document object. Whew.
var theHtmlNode = document.childNodes[0];
var theBodyNode = theHtmlNode.childNodes[1];
var theParagraphNode = theBodyNode.childNodes[1];
alert( "theParagraphNode is a " + theParagraphNode.nodeName + " node!" );Wonderful. It does exactly what we want. But it’s really quite verbose, and there's a much better way to write it. In the Objects article, you learned that you can chain object references together; you can do the same thing here, skipping the intermediary variables by writing the following:
var theParagraphNode = document.childNodes[0].childNodes[1].childNodes[1];
alert( "theParagraphNode is a " + theParagraphNode.nodeName + " node!" );This is much less verbose, and saves you a bit of code.
A node’s first child is always node.childNodes[0], and a node’s last child is always node.childNodes[node.childNodes.length - 1]. I access these quite often, but they are a bit unwieldy to type over and over again. Given how frequently useful they are, the DOM gives you explicit shortcuts for both: .firstChild and .lastChild respectively. Since the html node is the first child of the document object, and the body node is the last child of the html node, you could rewrite the above code even more clearly as:
var theParagraphNode = document.firstChild.lastChild.childNodes[1];
alert( "theParagraphNode is a " + theParagraphNode.nodeName + " node!" );These close-range node-navigation methods are useful, and let you get wherever you like in a document, but they’re cumbersome. Even in this tiny example document, you can start to see how laborious it can be to navigate from the root node down into the depths of the markup. There must be a better way to get around!
Direct access
It’s really very difficult to specify explicit paths to each of the elements you’re interested in on a page. Moreover, it becomes completely impossible if the page you’re working with is in any way dynamically generated (for example using a server-side language like PHP or ASP.NET) as you can’t guarantee that, for example, the paragraph you’re looking for is always the body node’s second child. So a better way is needed to get to a specific element without explicit knowledge of its surroundings.
Looking back at the HTML document in the example above, you can see that there’s an id attribute on the paragraph we just discussed. This id is unique, and identifies a specific location in the document that allows you to bypass the explicit path by using the document object’s getElementById method. The method does exactly what you’d expect, giving you back either null if you give JavaScript an id that doesn’t exist on the page, or the element node you’ve requested if it does exist. To test it out, let’s compare the results of the new method with the old:
var theParagraphNode = document.getElementById('excitingText');
if ( document.firstChild.lastChild.childNodes[3] == theParagraphNode ) {
alert( "theParagraphNode is exactly what we expect!" );
}This code will pop up the confirmation message, proving that the two methods give identical results for this example document. getElementById is the most efficient way of gaining access to a particular piece of a page: if you know you’ll need to do some processing somewhere on a page (especially if you can’t guarantee where) adding an id attribute in the appropriate place will save you time.
Equally useful is the DOM’s getElementsByTagName method, which returns a collection of all the elements on the page of a particular type. You can for example get JavaScript to show you all the p elements on the page. The following example gives us both the exciting paragraph, and its less interesting sibling:
var allParagraphs = document.getElementsByTagName('p');Processing the resulting collection stored in allParagraphs is best done with a for loop: you can work with it almost exactly like an array:
for (var i=0; i < allParagraphs.length; i++ ) {
// do your processing here, using
// "allParagraphs[i]" to reference
// the current element of the
// collection
alert( "This is paragraph " + i + "!" );
}For more complex documents, returning all elements of a given type might still be overwhelming. Instead of working through all 200 divs on a large page, it’s likely that you really just want to manipulate the divs from a specific section. In that case you can combine these two methods to filter your results: grab an element using its id, and ask it for all the elements of a given type that it contains. As an example, I could grab all of the em elements in my exciting paragraph by asking for the following
document.getElementById('excitingText').getElementsByTagName('em')Summary
The DOM is the foundation of almost everything JavaScript does for us on the web. It’s the interface that allows us to interact with our page’s content, and it’s essential to understand how to get around within that model.
This article has given you the basic tools for that job. You can easily traverse the DOM now using document to get a handle on the DOM’s root, and childNodes and parentNode to hop up and down the tree to nodes’ direct relatives. You can skip over intermediaries and avoid hard-coding long and cumbersome paths using getElementById and getElementsByTagName to create your own shortcuts. But climbing around in your tree is only the beginning.
The logical next step is to start doing interesting things with the results your JavaScript returns. You’ll need to grab data to power your scripts, and manipulate data on the page to create exciting user interactions. We’ll explore those topics in the next article, which shows you how to use methods the DOM provides to interact with nodes and their attributes, and to weave that interaction into the scripts and interfaces you create in the future.
Exercise questions
- Using the example document from the article, write three different paths that end up on the
headelement. Remember that you can chainchildNodesandparentNodetogether as much as you like. - Given an arbitrary node, how can you determine its type?
- Given an arbitrary node, how can you get back to the
documentobject? Hint: Remember that thedocumentobject’sparentNodeproperty returnsnull.
About the author

Mike West is a philosophy student cleverly disguised as an experienced and successful web developer. He’s been working with the web for over a decade, most recently on the team responsible for building up Yahoo!’s European news sites.
After abandoning suburban Texas’ wide open plains in 2005, Mike settled in Munich, Germany where he’s struggling with the language less and less every day. mikewest.org is his home on the web, (slowly) gathering his writings and links together for posterity. He keeps his code on GitHub.
This article is licensed under a Creative Commons Attribution, Non Commercial - Share Alike 2.5 license.
Comments
The forum archive of this article is still available on My Opera.
No new comments accepted.