XFN encoding, extraction, and visualizations
Introduction
In this article I will take a good look at XFN - the microformat for describing relationships between people. I will look briefly at what it is and the basic markup needed to add the information to your sites, before then going into depth, looking at the benefits you can get from that data by extracting it and using it in different ways. Extracting the data is easier than you think - there is probably a library for your favorite language already! If not, there are also some web services that could do the job that I'll show you below.
Note that I've created some complete examples to accompany the CSS and XSLT sections - you can download these here.
What is XFN?
XFN stands for XHTML Friends Network and is a very early microformat created by the Global Multimedia Protocol Group. It grew out of the common publishing trend of linking to other sites you enjoyed reading. On your blog, this is called a blogroll - it is common to think of people by their web sites. Their URL is a representation of that person; part of their online identity. XFN is an attempt to codify these relationships using standard HTML.
XFN is very easy to use - you simply use some intuitive keywords to describe the relationships you have with other people. There is an XMDP document that describes all the possible XFN keyword values. These values are very basic and capture a wide spectrum of possibilities. I will walk you through some examples below. XFN is purposely left vague; it allows for the definitions to more easily flex with time, and therefore we get a shorter list. A more verbose enumerated lists would otherwise be so long that you wouldn't be able to decide exactly which values to use, and it would never be fine-grained enough for everyone. So XFN fits 80% of use cases very quickly and easily, and using something like POSH or other microformats to fit edge cases.
These XFN values are added inside the rel attributes (rel is short for "relationship") of the a elements you use to link to these people. The rel attribute can also appear on the link element, but since microformats are concerned with more visible metadata, we only focus on the a element. A nice aspect of the rel attribute is that it can take a unordered space-separated set of values. This means that you can make compound XFN statements just by listing more than one value, if the person you are linking to has more than one different type of relationship to you. The following is a table of the possible XFN values, split into categories:
| Friendship (select one) | Physical | Professional | Geographical (select one) | Family (select one) | Romantic | Identity |
|---|---|---|---|---|---|---|
| contact | met | co-worker | co-resident | child | muse | me |
| acquaintance | colleague | neighbor | parent | crush | ||
| friend | sibling | date | ||||
| spouse | sweetheart | |||||
| kin |
Implementation
So lets take for example, Chris Mills, the editor of my article. He has an author bio on dev.opera.com, so we can use this link:
<a href="../../../author/974138" rel="">Chris Mills</a>Now that I have my basic structure, I need to put in the appropriate values for my relationship with Chris. If I just start at the left of the XFN list and work across, I can see what values I can use. The first category is Friendship, which describes the level of friendliness Chris and I have. I know how to contact Chris, so contact is certainly appropriate. For most people this might be the maximum relationship possible, but I know Chris better than that, so I could use acquaintance. I have also worked with Chris before on other projects and met him on several occasions such as SxSWi and d.Construct, and we have chatted over several beverages, so I think friend is the most suitable description. Some people reserve the term friend for people whom they would let watch their children, some people are friends with someone they simply met for 5 minutes or admire. In the friendship category, it is possible to only have one value, so I would mark Chris as a friend. The term friend is often symmetrical, meaning that if I consider Chris a friend, it is likely that he considers me a friend too, but that is not required. Chris could be much more strict about his definition of friend and only consider the few people on his Christmas card list worthy of that value. The definition of friend is open for interpretation and will change with context and time. Since the Friendship category can only have one value at most, I selected the highest fidelity relationship, friend.
<a href="../../../author/974138" rel="friend">Chris Mills</a>The next category is Physical. The only option is met, and I have met Chris on several occasions, so I can add that to the rel value as well.
<a href="../../../author/974138" rel="friend met">Chris Mills</a>The order of the XFN values is not important; just the fact that they are space separated means that all of these apply. The next category is Professional. These describe a few professional relationships that you could have had with people. Both Chris and I work in the same field and write for dev.opera.com, so I would say that he is a colleague. The other option is co-worker, but we don't both work for the same company, so I probably wouldn't use that. Both of these professional values are symmetric, so if I am a co-worker of Chris' then he is also a co-worker of mine, and the same for colleague - if we both work in the same field/area then we both should consider each other colleagues.
<a href="../../../author/974138" rel="friend met colleague">Chris Mills</a>In the rest of the categories, I don't find any matches for Chris, so I don't need to add any more values to my rel attribute.
The last category in XFN is Identity, and is only used for your own sites, not for friends' sites. The only rel value is me which, when symmetric, allows for identity consolidation across different pages on the internet. If my website suda.co.uk has a link to my flickr profile, I can use rel="me". Then on my flickr profile I can use rel="me" to link back to suda.co.uk. If I can do this over all my various profile pages on Twitter, upcoming and others. Then any XFN rel-me aware crawler can begin to build a single profile of me on the Web all without having to tell every single site about all my other profiles.
Tools to Create XFN
If this is too hard to remember, don't worry - there are plenty of tools to help you. There is a web version of the XFN creator in various languages to quickly get you started. There are also plug-ins for Dreamweaver and Wordpress. More and more plugins are constantly appearing, so be sure to check the XFN wiki page for your favorite language or CMS.
Issues with XFN
There have always been some open issues with XFN. I won't go into depth here, but below I will point out a few common sticking points and look at how we can benefit from taking note of them.
- There is no way to say, for example, ex-friend 1990-2000. XFN exists in the now. This is more of an edge case and can't be represented in XFN.
- The definition of 'friend' is perhaps too lose. This is a grey area - some think it is definitely too loose, and others say let the language evolve and the definition of friend change as well. I personally agree with the latter - if we strive to increase the accuracy of the terminology we could over-complicate things and end up with 400 extra definitions of friendship which no one would use anyway.
- XFN does not have enough professional relationships such as "manager" or "vendor". The great thing about HTML is that you could still write
rel="co-worker manager". An XFN parser would still find the 'co-worker' value and other specific parsers would extract your custom values such as 'manager'. Microformats are also based on publishing practices, so as more people publish their professional relationships, these could get folded into XFN at a later date. Nothing is frozen in perpetuity.
How do you extract XFN data?
There are plenty of different ways you can extract data from HTML, and I'll look at some of the more popular ones in this section.
JavaScript
Javascript naturally compliments HTML, so it is an ideal language to parse XFN from the DOM. The JavaScript could be loading into the page onLoad, it could be part of a bookmarklet, or even compiled into a greasemonkey script. Here is some simple code to get you started.
// get all 'a' elements
var links=document.getElementsByTagName("a");
var xfnValues=['friend','acquaintance','contact','met','co-worker','colleague','co-resident','neighbor','child','parent','sibling','spouse','kin','muse','crush','date','sweetheart','me']
// loop through and look for rel attributes
for(var i=0;i<links.length;i++){
var link = links[i];
// check to see if the link has an rel and href attribute
if(link.getAttribute("href")&&link.getAttribute("rel")) {
// get the rel value
var rel=link.getAttribute("rel");
// loop through the known XFN values
for(var j=0;j< xfnValues.length;j++) {
// check for matches
var regex=new RegExp('\\b'+ xfnValues[j]+'\\b',"i");
if(rel.match(regex)) {
// do something here
}
}
}
}Drew McLellan has a great tool called rel-Lint, which will help you find common problems with your XFN and other markup.
CSS
Using CSS you can easily style XFN data. There are lots of different ways to achieve this, including styling background colors, or using content :after to add an asterisk or an image. Wolfgang Bartelme has made several very nice images for this purpose that are generously licensed.
XFN values are added to the rel attributes of a elements. So the first part of any CSS statement would be to style the a, from there we will build up to styling specific XFN values.
a{ background-color: yellow; }That will give a yellow background to all links, but I need to be more specific here - next, I want to target just a elements with a rel attribute. This is possible with the CSS attribute selector.
a[rel] { background-color: yellow; }This will only apply the style to all links that also contain the rel attribute. The next step is to make sure that the rel attributes selected have an XFN values - we don't want just any rel attributes.
a[rel="friend"]{ background-color: yellow; }While this is correct, it will only find a elements that have a single rel value of friend. Remember that the rel attribute can take a space separated list of values. If there are other values on the rel attribute, this selector will not match and the style will not be applied. So I need to add another piece of information to my CSS selector syntax.
a[rel~="friend"]{ background-color: yellow; }Using ~=" instead of just = tells the browser to match the string friend in any list of space-separated values, as well as just friend on it's own. Note that this is not supported in IE6, but it is in most other modern browsers. Finally, it is also possible to chain these together:
a[rel~="friend"][rel~="co-worker"] background-color: red; }That allows you to style people combinations of XFN values, for instance, I might style friends in yellow, but friends that I also work with would have a red background. This is possible for any combination, friend vs. friend and colleagues, muse vs. muse and met; using CSS it is easy to target these special relationships.
XSLT
XSLT is designed to convert XML to another format - you can extract data from HTML using XSL and XPath very easily, as long as the HTML is well-formed. (If it isn't, you can use an application like TIDY to clean it up.) For all the people who are more familiar with Javascript than XPath, much of the DOM knowledge transfers over, you just need to familiarize yourself with the new syntax. Let me walk you through an example. First I need to find all a elements anywhere in the DOM Tree. To do this, I start with the // path.
//aThat will find any a element at any depth (//) from the root node, in our case html. It is much like document.getElementByTagName('a') in JavaScript. The next step is to refine our selection to all a elements that have a rel attribute of friend.
//a[@rel='friend']The brackets ([]) work in almost the same way as our CSS brackets. The @ is used to say that this is an attribute, so @rel is the rel attribute and it must be equal to friend. The problem with that XPath expression is the same as the CSS issue; it will find rel values that only contain the string friend; I want to find friend anywhere in a space separated list.
XPath gives us a few more tools than CSS; we can add the function contains() to find the string friend from within the whole rel attribute value. contains() takes two parameters - the full string followed by the substring you are looking for.
//a[contains(@rel,'friend')]This will find any a element that has a rel attribute that contains the substring friend. The problem is that it will also find the string friendship because friend is contained within it. To solve this, I can pad both sides of the rel attribute with spaces and search for the term also padded with spaces. It sounds complicated, but it isn't. There are two more functions to note in this example - normalize-space() which removes unneeded white-space (equivalent to trim() in other programming languages) and concat(), which just merges strings together. In this example we are concatenating an empty space before and after the normalized rel attribute.
//a[contains(concat(' ', normalize-space(@rel), ' '),' friend ')]Using XPath you can now find the elements that match your queries. It is now possible to extract that data and style it, transform it and save it for access later.
Regular Expressions
You can also use Regular Expressions to extract the data. This is more complicated, but some people are more comfortable with Regexes than XSLT. I'm not a Regular Expressions expert - there is probably a better, more optimized why to do this - but this works for me!
/<a(.*|\W*)(rel\s*=\s*\"([^\"]*)\")(.*|\W*)>(.*|\W*)<\/a>/iThat will find all the a elements and attempt to extract the rel values into an array that you can then parse to match any values; you can then do anything you want with the data.
The regular expression is case-insensitive; we specified that with the /i on the end. It starts off matching a string of <a - this is how every anchor link is written. Next, it looks for (.*|\W*). The period (. matches any character and the \W matches any word. We are looking for either of them zero or more times. This will eat-up any other text such as href="..." or other attributes that are not the rel values we are looking for. We need to do this again after the rel value to eat-up any text behind it as well. The href or other attributes can be in any order, so we need to handle those scenarios. The really important part is (rel\s*=\s*\"([^\"]*)\"). This matches the string rel followed by zero or more white-space characters, then an = followed by more optional white-space. The \" is the escaped value for a double-quote character. This is the start of our space separated list of rel values. The ([^\"]*) tells my regular expression to grab zero or more characters that are not (^) a double-quote.
Once you run that regular expression, all the data within the parenthesis is collected in array values. The actual value of the rel attribute would be in array item [3] because it is the third set of parenthesis in that string. This is quite complicated for something that seems pretty simple in other languages, but depending on your situation, comfort level and programming language, regular expressions might be the best choice for you.
If none of those snippets are your cup of tea, there might be one available in your favorite language. The XFN wiki page has a growing list of applications and libraries already written, so that is an excellent place to start for your next XFN project.
What can we do with this data?
So this is all well and good, but some of you must be thinking "What interesting things can I now do with this data, now I've extracted it"? Once you have extracted all of this data from the HTML, it is easy to store in a database or text file for retrieval later. You are basically storing three pieces of data - two URLs (one URL#1 that has an XFN relationship with the second URL) and an XFN relationship type (the value of the rel attribute.) Once you have your database, you can ask questions such as "Show me all URLs that have a relationship of 'contact or colleague' with 'suda.co.uk'"
In this section, I will look at some use cases and sites that allow you to do some of this today.
Six Degrees of Separation
The famous Small World Phenomenon by Stanley Milgram demonstrated that there is on average of 6 steps between any two people. This was done through a complex network of letter sending, and then later on again via email. Using XFN it is possible to map distances between two people via their relationships. The site RubHub tracks XFN relationships and lists who links to you and how, along with who you link to and how. The results for my personal site, suda.co.uk, can be seen in Figure 1. My friend Harry Halpin from my University days links to me and in my example above, I link to Chris Mills. So an automated spider could begin to build a network of who is connected to who and through whom. We can expand that through Harry's contacts and Chris's, and we can ask who knows who and in how many hops, or what other mutual connections there are between the two parties. Previously, without XFN, you could only guess if a link defined a relationship or if it was just a link. Now that we have "typed" the links, it is possible to extract more meaning from them.
There is no tool that I know of which can answer questions such as "how far is Jeffrey Zeldman from Brian Suda". The RubHub service allows you to click through to each person's site and follow their links ad infinitum, much like you can do with IMDB to see which actors have worked with with others. This sort of data is just asking for a nice visual front-end to be built, so you can ask questions like "Find the path between suda.co.uk and zeldman.com". Now, if only Kevin Bacon had a website with XFN...
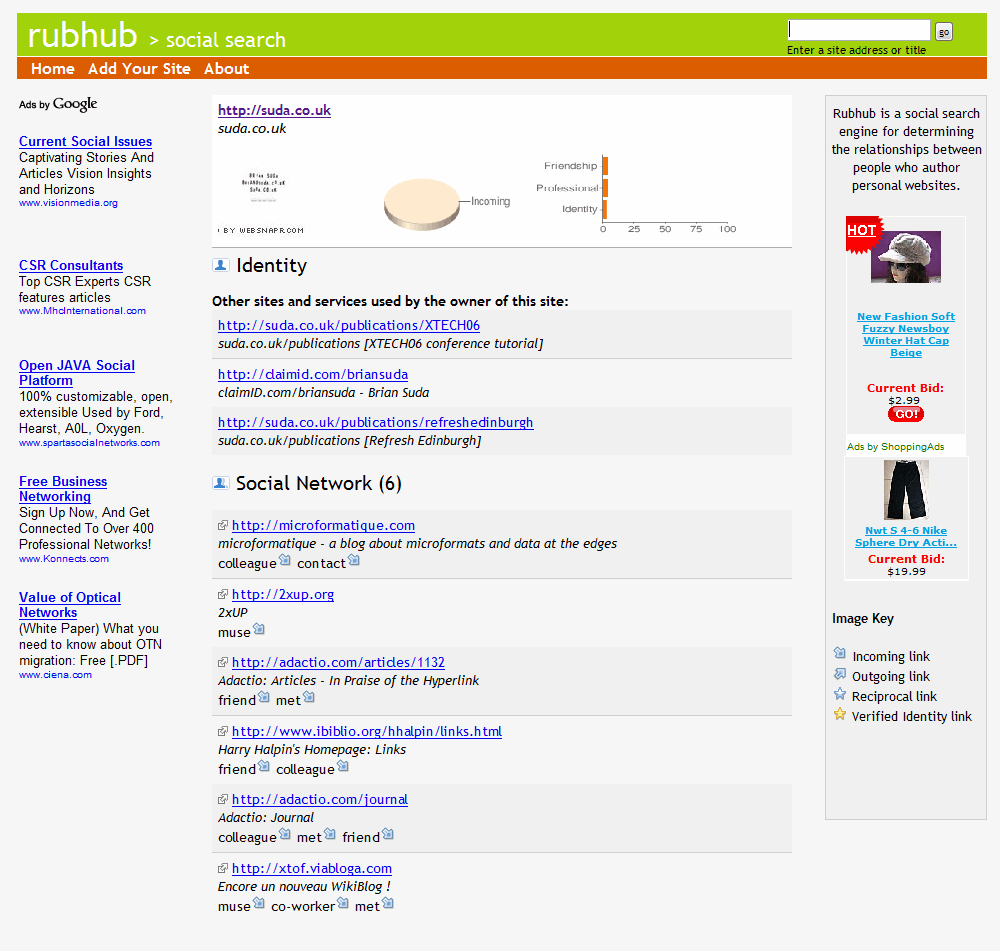
Figure 1: suda.co.uk RubHub XFN results
As you can see, the RubHub spider has found 6 external links that point back to suda.co.uk with various types of XFN value. Rubhub also participates in identity consolidation through the use of rel-me links - it knows that there are 3 other pages that I have claimed to be mine. This means that any XFN link to any of those 3 pages should be counted as a link to suda.co.uk.
XFN Graph
XFN Graph is a similar application to IBM's Many Eyes, which I mentioned in a previous article. You seed this application with a URL and a depth. It will then crawl the URL and links to the specified depth looking for XFN data. This allows you to build a connected graph between people. From this you can easily inspect the nodes and edges to find a path between any two people.
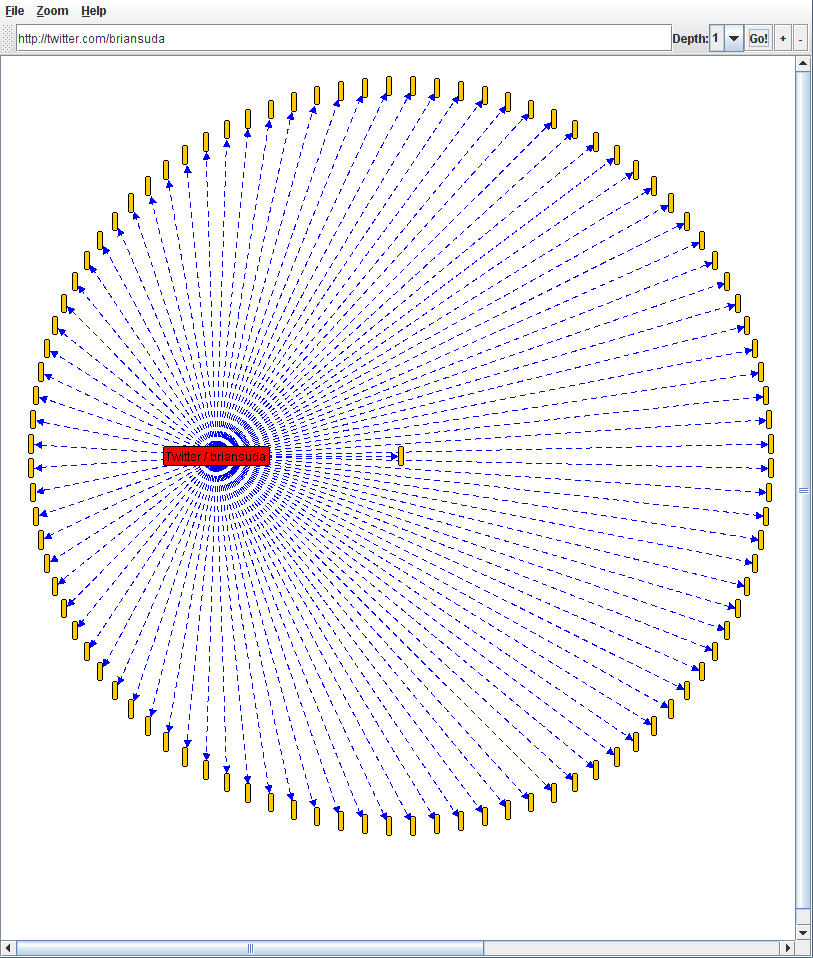
Figure 2: XFN Graph of Brian Suda's friends from Twitter.
The example in Figure 2 only goes to a depth of 1, but it is possible to continue to crawl each of those nodes and find their friends. With a depth search of 2 it becomes possible to search friends of friends, with a depth of 3 you get friends of friends of friends and so on.
Combining this data with supplementary information allows for some interesting mash-ups, for example you could combine your email's sent folder with your XFN friends list to match your friends with the frequency you e-mail them. You could also use twitter's @username to see which people are talking to who most frequently.
Tag Clouds
The backnetwork is a piece of software for conferences and other gatherings. It allows you to add yourself and some personal information, then you can slowly build-up your relationships with other event attendees. It has many interesting feature, but the one I'll focus on is the relationship tag cloud.
As you connect with other event goers, you label them with XFN values in the system. The relationship cloud tags those XFN values and assigns weights to them. A friend is larger than an acquaintance, which is in-turn larger than a contact. If the relationship is reciprocal then the size is further increased. This goes back to the example of myself and Chris. I consider him a friend, but it might be reciprocal. In that instance, the size of the name would not be as larger as if it where. Using this odd pairing, we can begin to also weight the strength of ties, not just the type.

Figure 3: d.Construct backnetwork relationship cloud
Figure 3 shows my Tag Cloud from d.Construct 07 - you can easily see who I am connected to and how strongly. Cloud type visualizations are popular for tags and word breakdowns, but they can also be used for people and the strength of the connection. This allows you to see at a quick glance who you are most connected with. Most of the time, people are not interested in exactly HOW you may know someone, but that the connection is big and strong. If you want to be introduced to someone in particular, then you can see which or your friends have the strongest connection to that person. That is the route with the most success.
Building your own XFN spider
Building your own spider is probably not advisable. Writing the code, traveling the web, indexing sites for links ... while you're at it, why not just write an entire Internet search engine? Fortunately you have a few options. For those who just must roll their own applications, you could rent data and server time from Alexa and crawl the data for yourself, or you could use the new Google Social Graph API. This allows you to enter one or more URLs; it will then look in its own Internet database for links to and from those URLs that have XFN or FoaF links. I entered suda.co.uk, my personal site, and claimid.com/briansuda, another site that I use for OpenID. The results of what it found are amazing - check out Figure 4.
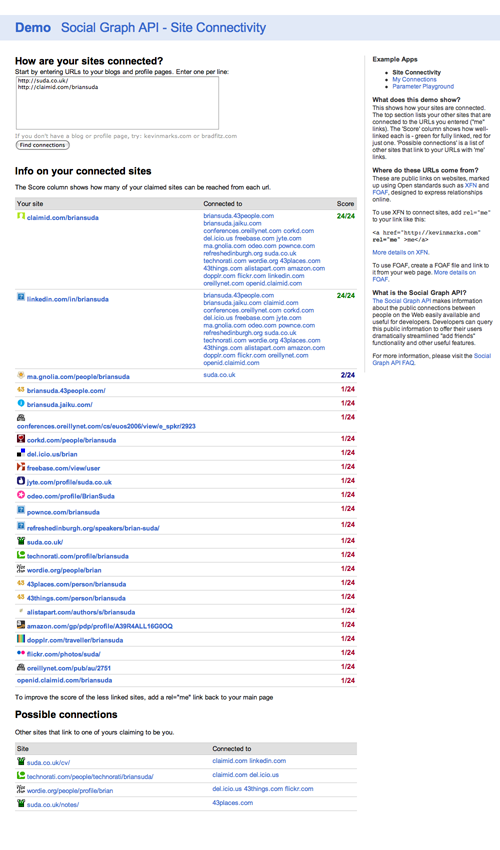
Figure 4: Screen Shot of my connected URLs in the Google Social API
The service finds 25 URLs that it knows are also me, and 4 more that it thinks are me. This service allows for you to consolidate your identity across the entire internet. It epitomizes what the internet was designed for, loosely coupled sites, without the need for a central server where you enter all your information. You can live your life at the edges of this graph on websites that do each task as they were designed. Then services can gather all that data together to make a single profile about you.
This not only works for data about you, but also data about how you relate to friends. The functionality found at the above link allows for any new social networking site to ask you for a URL as you join. It can then use the Google API to get a list of friends' URLs that you have declared elsewhere on the internet. This new social networking site has no requirement for you to spend hours writing code to access various sites' APIs or scrap them for data; you can now ask a single service which has previously indexed the sites and relationships. Google returns the data, suggesting potential URLs that match existing members of this new social network and asking you to migrate your relationships with just a click.
Summary
As we have seen, XFN is a quick and simple way to express some basic relationships between yourself and others through the use of existing HTML practices. By marking-up data explicitly, you are giving more meaning to your mark-up, which can then be used to generate interesting new visualizations and used to create a network of connections that can easily be moved from place to place. So what are you waiting for?
Resources
- Social Network Visualizations
- Social Graph Problem
- List of friend list supporting XFN
- the Google Social Graph application
Brian Suda

Brian Suda works at TM Software http://tm-software.com/ where he tinkers on enterprise websites working in new technologies and streamlining the customer experience.
This article is licensed under a Creative Commons Attribution, Non Commercial - Share Alike 2.5 license.
Comments
The forum archive of this article is still available on My Opera.
-

I am glad to found such useful post. I really increased my knowledge.
No new comments accepted.applyinnovations
Friday, February 15, 2013